
英语原文共 37 页,剩余内容已隐藏,支付完成后下载完整资料
外外文文献翻译
均值漂移:一种用于特征空间分析的强健算法
摘 要
针对多峰特征空间分析,本文提出一种通用的非参数计算方法,用来描绘多峰特征空间下任意形状的集群。本算法的基本计算模型是一种古老的模式识别过程,均值漂移算法。经证明,离散数据可以在均值漂移的递归过程中收敛到其密度函数的极值点,这样,就显示出它在检测密度模式方面的实用性。本文确立了Nadaraya Watson 估计量到内核回归和强健的M估计量位置关系的均值漂移过程。可应用于两个低级别的视觉任务:连续平滑的保持和图像分割。在这些算法当中,仅需知道要分析图像的分辨率,灰度图像、彩色图像均可作为输入图像。大量的实验结果说明了这种算法的巨大优越性。
关键字:均值漂移,集群,图像分割,特征空间,低阶视域
第1章 绪 论
通常,人们误认为低阶视域工作比较难做。它经常需要依赖准确猜测需要调整的参数才能应用到相关技术当中,并且容易出错。为了提高计算性能,低级别工作的执行方式应该为任务驱动,即由高级信息独立支持。然而这种方法也需要满足几个条件:第一,低级视域能提供足够可靠的输入图像信息。第二,特征提取过程仅由少量与输入域测量直接相关的调整参数来控制。
基于特征空间的图像分析是一个典型的低阶视域案例,它满足上文所述的几个要求。特征空间是处理完成一次小的子集数据后得到的输入映射。对于每个子集,我们均可得到其感兴趣区域的特征参数表示,并将结果映射到参数的一个多维空间点中。整个输入被处理后,就得到与特征空间有关的显著特性,如集群。分析的目的就是将这些集群划分。特征空间具有不受应用场景约束的性质。在映射当中使用的子集范围可以从单个像素(如图像的彩色空间表示)到一系列准随机选择的数据点集(如霍夫变换概率)。特征空间的优点和缺点均源于输入派生形式的整体性。一方面,所有描述显著特征的因素都集中在一处出现,提供优良的噪声容忍性,但这可能会导致不可靠的局部判定。另一方面,特征空间中某些特征尽管有特殊的作用,但因为缺少高级信息的支持,可能无法被监测到,然而这个缺点在很大程度上可以通过输入域额外的(空间)参数增强特征空间或者功能强大的特征空间分析结果主导的输入域后处理功能来避免。
特征空间分析是独立于应用的。虽然现已问世多种集群技术,但他们中的大多数仍不能用于分析实时数据的特征空间。那些依赖于集群表示的先验知识方法(包括那些利用进行全球性优化的数据)以及假设空间中的所有集群拥有相同的形状(经常假设为椭圆)的方法,也不能有效的处理实时特征空间的复杂性。有关这方面的近期动态,请参阅【29,第八节】。
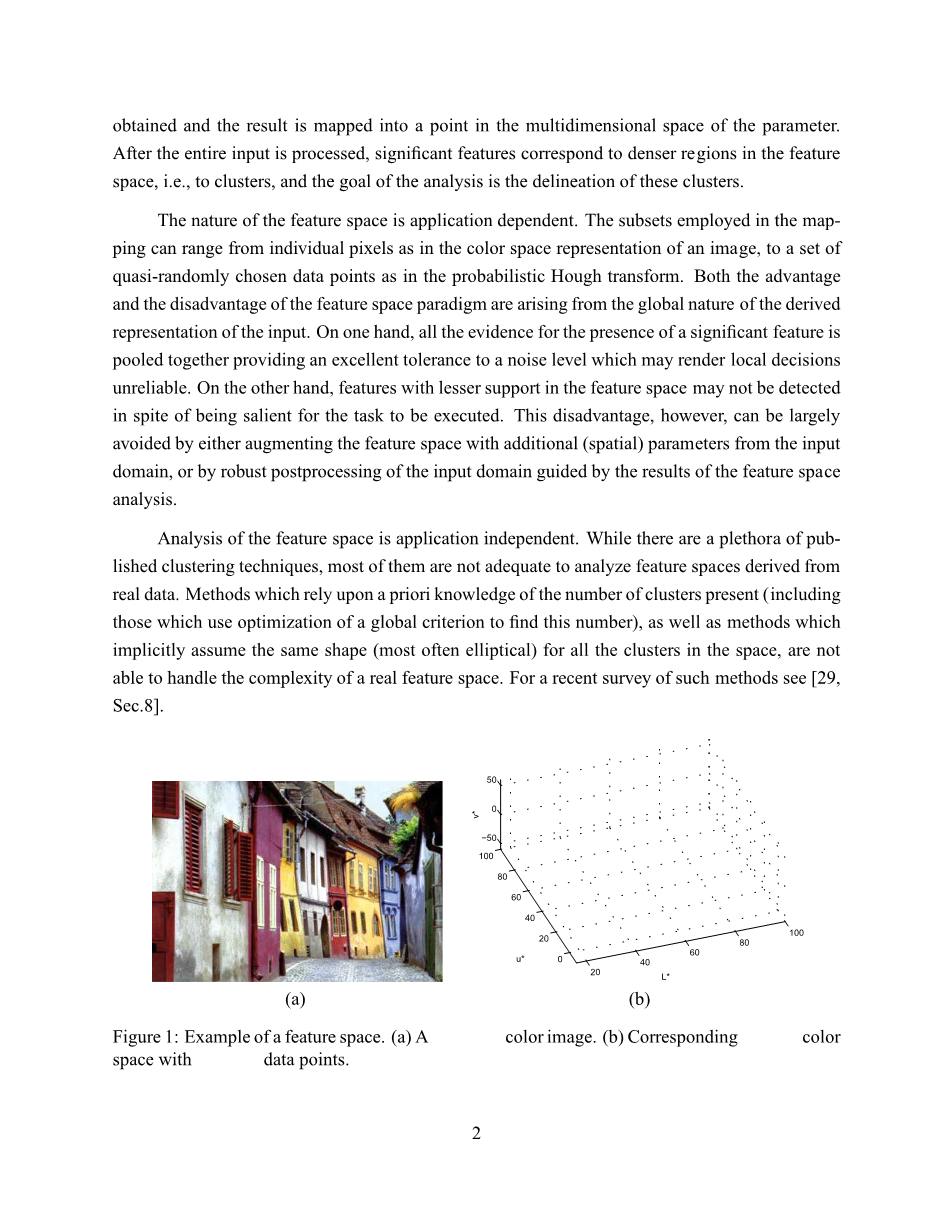
(a) 一幅彩色图像 (b)对应的Luv颜色空间
图1.1 特征空间示例
图1.1阐述的是一个典型的例子。图1.1(a)所示的彩色图像映射到三维L U V 色彩空间(将在第四节进行讲述)。主色彩产生的集群中存在连续过度,空间被分割成椭圆切片后将导致严重的伪影。对这样的数据强迫使用混合高斯模型是行不通的,例如【49】,对于这类复杂的案例,即使使用混合高斯密度的强健算法也很难达到目的。同时注意到混合模型需要集群数据作为参数,而这样做,本身就有难度。详见【45】,文中提出了确定参数的几种不同方法。
任意结构的特征空间只能通过非参数的方法进行分析,因为这些方法不需要先验知识。很多文献已经介绍了大量的非参数集群方法,它们大致可以分为两大类:分类群聚和密度估计。分级群聚依据对邻近数据的度量整合或分割数据,有关分类群聚的方法描述参见【28,第3.2节】。分类技术的计算量很大,并且有意义的数据融合或分离停止准则不明确。
可以使用基于非参数集群密度估计是因为特征空间可以看做空间参数的实验概率密度函数。特征空间的密集区域与实验概率密度函数的极大值有关,也就是说与未知密度模式有关。一旦确定模式的位置,根据特征空间的局部特性,与之相关的集群便可进行划分了。【25】【60】【63】。
本文所介绍的模式识别方法及集群方法基于均值漂移算法,由Fukunaga 和Hostetler [21]在1975年提出,但一直不被重视。直到Cheng发表的一篇论文才点燃了学术界对它的热忱。尽管均值漂移算法拥有良好的特性,但在统计领域人们对此知之甚少。虽然【24,第6.2.2】在书中讨论过此方法,但是均值漂移算法在密度估计领域的优点也是最近才被重新发现【8】。
正如我们在下文中介绍的一样,在特征空间分析上,基于均值漂移的计算模型是一种非常万能的工具,针对很多视频任务,它都可以提供可靠的解决方式。本文的第二部分介绍了均值漂移的基本概念及性质。在第三部分,均值漂移作为一种计算模型用于强健的特征空间分析,并讨论了其可行性。在第四部分,将特征空间分析技术应用到两类低级视域任务上:不连续持续滤波和图像分割。这两种算法均可作为灰度或彩色图像的输入,操作者唯一需要知道的参数只是图像的分辨率。均值漂移算法的应用并不仅局限于本文所呈现的几个例子。第五部分介绍了均值漂移的其他应用,并将其放在一个更为一般的背景下予以讨论。
第2章 均值漂移算法
核密度估计(在模式识别领域被称为Parzen 窗口技术【17,第4.3节】)是应用最广泛的密度估计方法。设d维空间Rd 中有n个数据点xi,(i=1,2,hellip;n),点x关于核函数和dtimes;d的对称正定宽带矩阵H的多元核函数估计为
(2.1)
其中
(2.2)
d变量核K(x)是具有紧凑支持的有界函数满足以下条件
(2.3)
(2.4)
其中cK是常数。 多元核函数可以由径向奇函数以两种方法合成
(2.5)
其中通过径向基的乘积得到,通过在空间中旋转合成,即是径向对称的。系数保证的积分为1。多元核函数均满足(3)式,但放射对称核函数更符合我们的要求。
我们仅对满足(5)式的放射性对称核函数感兴趣,在X它只需定义核函数的配置函数
(2.6)
在足够定义函数的情况下它被称为核函数的外形,只是针对的情况。使结合成整体的常量 ,一定是取的正数。
使用一个完全参数化的变量H增加估计的复杂度,并且在实际中,带宽基值H被选择为对角矩阵,或者和对角矩阵成比例的矩阵。后面一种情况最明显的优点是只需要提供一个大于0的带宽参数,然而,由式(2.2)可以看出,对特征空间的一个欧几里德公制的正确性必须首先被确认。只需要征用一个带宽参数,核函数密度估计值(2.1)就变成了著名表达式
(2.7)
一个核函数密度估计值的特征是由密度值和它的估计值中间的空间误差的均值来测量的,跨越了定义的范围。然而在实际中,只能计算这个测量值的一个渐进近似值。在这个渐进值下面,数据的点数n趋向于无穷,同时带宽h以低于n-1的速度趋向于0。对于两种多元核函数来说,AMISE 测量值被epanechnikov核函数减小到最低,有如下关系
引申出如下放射均衡核函数
(2.8)
在这里, (2.9) 是D维球体单元的体积。需要注意的是epanechnikov核关系在分界线附近是不可区分的。关系式
(2.10)
引申出多远常规核函数
(2.11)
对于两种类型的运算。常规核函数经常为了获得有限的支持而被两边对称地截掉。
尽管这两种核函数可以满足绝大多数的需要,我们仍然对如下展示出的结果对任意条件下的核函数都是正确的产生兴趣。通过引用加标记的关系式,密度估计值(2.7)可以被重新写成如下形式
(2.12)
在对有基本密度值f(x)的特征空间进行分析的第一步就是找出此密度值的模式。这个模式位于梯度的所有零点中,并且均值漂移程序是一种不需要进行密度估计就能找出这些零点的简介方法。
2.1密度梯度估计
密度梯度的估计量是通过利用式(2.12)的线性特性作为密度估计函数的梯度而得到的
(2.13)
我们定义如下函数
(2.14)
假设核函数的派生量取自所有大于0的值,除了某些限定值。现在,利用g(x)来表示其外形,核函数G(x)可以被定义如下
(2.15)
在这里是对应的标准化常量。核函数被称为(2.8)中在有微小差别的环境下的阴影。注意Epanechnikov核函数是同类核函数的阴影,D维球体单元,同时常规核函数和它的阴影有相同的表达式。
将g(x)代入(2.13)式,得:
(2.16)
式中为正数。这个条件在实际中对所有的轮廓函数都很容易满足的。在式(2.16)中乘积的两个项都很重要。在式(2.16)中,第一个项是和通过
核函数计算出来的密度估计值x成比例
(2.17)
第二个项是均值漂移向量
(2.18)
即与加权均值方法不同的是使用表示权值,为核(窗口)的)中心,根据(2.17)(2.18),(2.16)变成
(2.19)
(2.20)
表达式(2.20)显示在X的位置,通过核函数计算出来的均值漂移矢量和通过核函数K得到的常规密度梯度估计值成比例。标准化是由在核函数计算出的x值得到的密度估计值。均值漂移矢量通常指向密度最大值增加的方向。这是个关于性能更普遍的表达,被Fukunaga和Hostetler首次阐述,并且在(2.8)中进行了讨论。
在(2.20)中获得的关系式是靠直觉得到的,局部均值向着大多数点所在的区域漂移。既然均值漂移矢量是和局部梯度估计值相对应的,那么它就可以定义一个指向估计密度值的路径。密度的模式就是这样的一些静止点。
通过均值漂移矢量,核函数(窗) 发生变化,确保汇聚到到使(2.12)式增益为0的点,在下节中,我们会对此进行介绍。密度估计的标准化呈现是一个显著的特征。对于特征空间中不感兴趣的低密度值区域分析,均值漂移算法比较复杂。类似的,在局部极大值点处,均值漂移算法步骤比较简便,分析过程也更精练。这样,均值漂移算法是一种适应强的自下而上的方法。
特征空间的稳态分析方法
多模态和集群的任意性是实时特征空间的既定特性。均值漂移算法具有的向极大值点聚集的特性使之成为类似空间分析的理想计算模型。为了能够检测到所有的特征模型,2.3节给出的基本算法在初始化时应覆盖整个特征空间,并运行多次(并行运行)。
在执行分析操作之前,需要强调两个重点(或者相关重点)问题:特征空间的大小及核的形状。从输入域到特征空间的映射往往为非欧几里得空间。颜色表示的问题将在第四节讨论,但是我们所使用的参数则需要小心求证,即使是在像霍夫线空间这样的简单案例中,如【28】【31】。
通过足够的矩阵宽带可以调整马氏度量。然而在实践中,最好还是保证特征空间为欧几里得度量,这样,带宽矩阵就由一个参数控制。为使所有的均值漂移算法在特征空间中使用相同的核形状,必要条件是在显著模式下的局部密度变化不像其他显著模式下那样变化很大。
均值漂移过程开始的点应选择那些有内核(窗口)镶嵌在整个功能空间(非常稀疏的地区除外)的。不需要常规的镶嵌图形。因为窗口朝着模式化的方向演化,几乎所有的数据点都会被访问到,这样,所有在特征空间捕捉到的信息都可以使用。应当注意的是,由于迭代阈值的终止,收敛到一个给定模式时将会发生轻微的偏差。同样,在平稳的停滞期,梯度值约等于0,均值漂移过程也会停止。
通过后期处理,这些系统产出很
剩余内容已隐藏,支付完成后下载完整资料
资料编号:[139850],资料为PDF文档或Word文档,PDF文档可免费转换为Word
您可能感兴趣的文章
- 饮用水微生物群:一个全面的时空研究,以监测巴黎供水系统的水质外文翻译资料
- 步进电机控制和摩擦模型对复杂机械系统精确定位的影响外文翻译资料
- 具有温湿度控制的开式阴极PEM燃料电池性能的提升外文翻译资料
- 警报定时系统对驾驶员行为的影响:调查驾驶员信任的差异以及根据警报定时对警报的响应外文翻译资料
- 门禁系统的零知识认证解决方案外文翻译资料
- 车辆废气及室外环境中悬浮微粒中有机磷的含量—-个案研究外文翻译资料
- ZigBee协议对城市风力涡轮机的无线监控: 支持应用软件和传感器模块外文翻译资料
- ZigBee系统在医疗保健中提供位置信息和传感器数据传输的方案外文翻译资料
- 基于PLC的模糊控制器在污水处理系统中的应用外文翻译资料
- 光伏并联最大功率点跟踪系统独立应用程序外文翻译资料


