
英语原文共 24 页,剩余内容已隐藏,支付完成后下载完整资料
语言模型是无监督的多任务学习者
摘要
自然语言处理任务(例如问答,机器翻译,阅读理解和摘要)通常通过对特定任务数据集的监督学习来实现。我们证明,当对数百万个名为WebText的网页的新数据集进行训练时,语言模型开始学习这些任务而不需要任何明确的监督。当以文档和问题为条件时,语言模型生成的答案在CoQA数据集上达到55 F1 - 达到或超过4个基线系统中的3个的性能而未使用127,000 个训练样例。语言模型的容量对于zero-shot任务迁移的成功至关重要,并且增加它可以跨任务以对数线性方式提高性能。我们最大型号的GPT-2是一个1.5B参数的Transformer,它在zero-shot设置中的8个测试语言建模数据集中的7个中实现了最先进的结果,但仍然不适合WebText。模型中的样本反映了这些改进,并包含连贯的文本段落。这些发现为建立语言处理系统提供了一条很有希望的方向,该系统学会从自然发生的示范中完成任务。
介绍
机器学习系统现在通过将大型数据集,高容量模型和监督学习(Krizhevsky et al., 2012) (Sutskever et al., 2014) (Amodei et al., 2016)结合在一起训练,而在他们的具体任务方面表现优异。然而,这些系统是脆弱的,并且对数据分布的微小变化(Recht et al., 2018)和具体的任务敏感(Kirkpatrick et al., 2017)。目前的系统被更好地描述为狭隘的专家而不是称职的通才。我们将转向更通用的系统,它可以执行许多任务 - 最终无需为每个任务手动创建和标记训练数据集。
创建ML系统的主要方法是收集训练的样本数据集,演示所需任务的正确行为,训练系统去模仿这些行为,然后在独立同分布(IID)的held-out示例上测试其性能。这有助于在狭隘的专家方面取得进展。但是,输入的多样性往往会加剧字幕模型(Lake et al., 2017),阅读理解系统 (Jia amp; Liang, 2017)和图像分类器 (Alcorn et al., 2018) 行为的不稳定性。
我们怀疑单一领域数据集的单一任务训练的普遍性是当前系统缺乏一般化的主要原因。在具有当前架构的鲁棒系统方面的进步可能需要在更广泛的领域及任务上进行训练和性能测试。最近,已经有几个基准,例如GLUE(Wang et al., 2018)和decaNLP (McCann et al., 2018)开始研究这个问题。
多任务学习(Caruana,1997)是一个提高通用性的有前途的框架。然而,NLP的多任务训练仍处于初期阶段。最近的工作显示了适度的性能改进(Yogatama et al., 2019) ,迄今为止最雄心勃勃的两项努力分别培训了10对和17对(数据集,目标)(McCann et al., 2018) (Bowman et al., 2018)。从元学习的角度来看,每个(数据集,目标)对是从数据集和目标的分布中抽样的单个训练样本。当前的ML系统需要数百到数千个样本来诱导函数的通用性。这表明多任务训练很多都需要与现有方法一样多的有效训练对来实现其承诺。很难继续扩大数据集的创建和目标的设计,以达到使用现有技术来强制我们的方式所需的程度。这有助于探索执行多任务学习的其他设置。
当前表现最佳的语言任务系统结合了预训练和监督微调。这种方法历史悠久,趋向于更灵活的迁移形式。首先,学习单词向量并将其用作特定任务体系结构的输入 (Mikolov et al., 2013) (Collobert et al., 2011),然后转移循环网络的语境表示 (Dai amp; Le, 2015) (Peters et al., 2018),并且最近的工作表明,不再需要特定任务的架构,只需迁移带有许多自我关注的块就够了 (Radford et al., 2018) (Devlin et al., 2018)。
这些方法仍然需要监督训练才能执行任务。当只有极少或没有监督数据时,另一项工作证明了语言模型执行特定任务的前景,例如常识推理 (Schwartz et al., 2017)和情感分析 (Radford et al., 2017)。
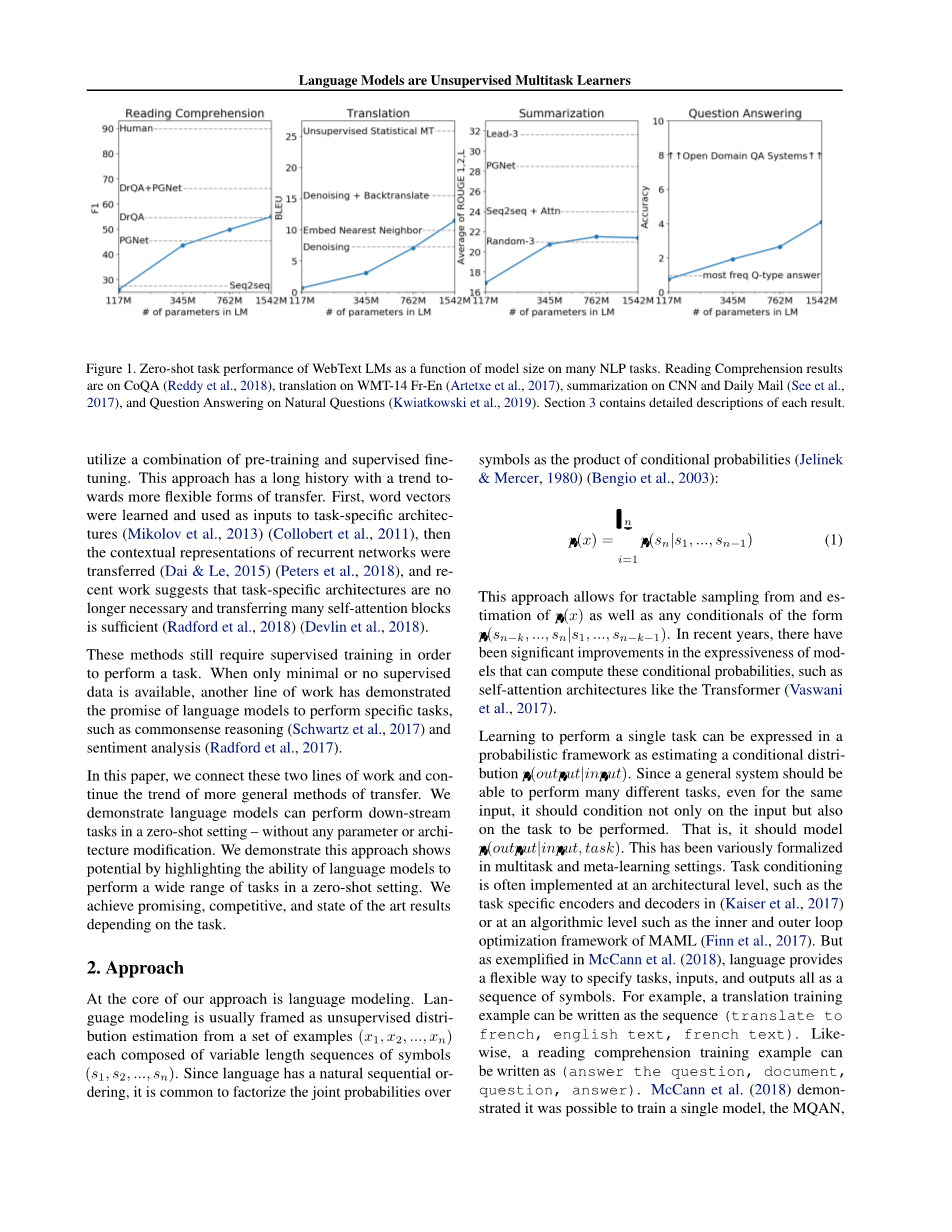
在本文中,我们将这两个工作线连接起来,并继续采用更一般的转移方法。我们演示语言模型可以在 zero-shot 设置中执行下游任务 - 无需任何参数或体系结构修改。我们通过强调语言模型在zero-shot设置中执行各种任务的能力来证明这种方法具有的潜力。我们根据任务获得有前途,有竞争力和最先进的结果。
方法
我们方法的核心是语言建模。 语言建模通常被构造为来自一组示例(x1,x2,...,xn)的无监督分布估计,每个示例由可变长度的符号序列(s1,s2,...,sn)组成。 由于语言具有自然的顺序排序,因此通常将符号上的联合概率分解为条件概率的乘积(Jelinek&Mercer,1980)(Bengio et al。,2003):
该方法允许从p(x)以及形式p(snminus;k,...,sn∣s1,...,snminus;kminus;1)的任何条件中进行易处理的采样和估计。近年来,那些可以计算这种条件概率的模型的表现力取得了显着的成就,例如像Transformer这样的自关注架构(Vaswani et al., 2017)。
学习执行单个任务可以在概率框架中表示为估计条件分布p(output∣input)。由于一般系统应该能够执行许多不同的任务,即使输入相同,它也不仅要考虑输入,还要考虑待执行的任务。也就是说,它应该对p(output∣input,task) 建模。在多任务和元学习设置中,它已经被各种形式化。任务调节通常在架构级别实施,例如(Kaiser et al., 2017)中任务特定的编码器和解码器,或者其在算法级别,例如MAML的内部和外部循环优化框架 (Finn et al., 2017)。但正如McCann et al. (2018)所举例说明的那样,语言提供了一种灵活的方式来将任务,输入和输出全部指定为一系列符号。例如,翻译训练样本可以写为序列(翻译为法语,英语文本,法语文本)。同样,阅读理解训练的例子可以写成(回答问题,文档,问题,答案)。McCann et al. (2018) 证明了可以训练单个模型MQAN,用这种类型的格式推断和执行许多不同的任务。
原则上,语言建模也能够学习McCann et al. (2018)的任务,而无需确定哪些符号是待预测的输出的明确的监督。由于监督目标与无监督目标相同,但仅在序列的子集上进行评估,因此无监督目标的全局最小值也是监督目标的全局最小值。在这种轻微的玩具环境中,密度估计作为 (Sutskever et al., 2015) 中讨论的根据原则训练目标的担忧是侧面步骤。相反,问题在于我们是否能够在实践中优化无监督的目标以进行收敛。初步实验证实,足够大的语言模型能够在这种玩具设置中执行多任务学习,但学习速度比明确监督的方法慢得多。
虽然从上述适当的设置到“野外语言”的混乱是一大步,但Weston(2016)在对话的背景下认为需要开发能够直接从自然语言中学习的系统并展示了一个概念证明 - 通过使用教师输出的前向预测来学习没有奖励信号的QA任务。虽然对话是一种有吸引力的方法,但我们担心它过于严格。互联网包含大量可被动获取的信息,无需交互式通信。我们的推测是,具有足够能力的语言模型将开始学习推断和执行自然语言序列中演示的任务,以便更好地预测它们,无论其采购方法如何。如果语言模型能够做到这一点,它实际上将执行无监督的多任务学习。我们通过在各种任务的zero-shot设置中分析语言模型的性能来测试是否是这种情况。
训练数据集
大多数先前的工作在单个文本域上训练语言模型,例如新闻文章(Jozefowicz等,2016),维基百科(Merity等,2016),或小说书(Kiros等,2015)。我们的方法旨在尽可能地构建尽可能大且多样化的数据集,以便在尽可能多的域和上下文中收集属于任务的自然语言演示。
一个有前景的、多样化的和几乎具有无限文本的数据来源是网络搜索,例如Common Crawl。虽然这些档案比当前语言建模数据集大许多个数量级,但它们具有重要的数据质量问题。 Trinh amp; Le (2018) 在共同推理的工作中使用了Common Crawl,但也提示到其大量文档“大部分内容都是难以理解的”。我们在使用Common Crawl进行的初始实验中发现了类似的数据问题。 Trinh&Le(2018)的最佳结果是使用Common Crawl的一个小子样本实现的,该子样本仅包含与其目标数据集最相似的文档,即Winograd Schema Challenge。虽然这是一种提高特定任务性能的实用方法,但我们希望避免对提前执行的任务做出假设。
相反,我们创建了一个新的网页刮板,强调文档质量。为此,我们只抓取了由人类策划/过滤的网页。手动过滤完整的网络搜索将非常昂贵,作为一个起点,我们从社交媒体平台Reddit中删除了所有出站链接,该平台至少获得了3个karma。这可以被认为是一个启发式指标,用于判断其他用户是否发现链接有趣、有教育意义或有趣。
生成的数据集WebText包含这4500万个链接的文本子集。 要从HTML响应中提取文本,我们将Dragnet(Peters amp; Lecocq, 2013) 和 Newspaper 内容提取器组合起来使用。 本文中提供的所有结果都使用了WebText的初步版本,该版本不包括2017年12月之后创建的链接,并且在删除重复数据并做了一些启发式的清理之后,包含略多于800万个文档,总共40 GB的文本。 我们从WebText中删除了所有维基百科文档,因为它是其他数据集的通用数据源,并且训练数据与测试评估任务的重叠会使分析复杂化。
输入表示
通用语言模型(LM)应该能够计算(并且还生成)任何字符串的概率。当前的大规模LM包含有像小写字母转化、标记化和词典外标记(out-of-vocabulary tokens)之类的预处理步骤,这限制了可模型化字符串的空间。将Unicode字符串作为一系列UTF-8字节处理的方式,优雅地满足了这一要求,如Gillick et al. (2015)的工作中所例证的那样。当前的字节级LM与大规模数据集上的字级LM不具竞争力,例如十亿字基准(One Billion Word Benchmark) (Al-Rfou et al., 2018)。我们在WebText上训练标准字节级LM的尝试中观察到了类似的性能差距。
字节对编码(BPE)(Sennrich et al., 2015)是字符和字级语言建模之间的可行的中间点,其在 频繁符号序列的字级输入 和 不频繁符号序列的字符级输入 之间进行的插值很有效。与其名称相反,现在涉及的BPE通常在Unicode代码点而不是字节序列上实现和运行。这些实现需要包括Unicode符号的完整空间,以便为所有Unicode字符串建模。在添加任何多符号标记之前,这将使基本词汇量超过130,000,与通常一起使用的32,000到64,000个token词汇表相比,这是非常大的。相反,BPE的字节级版本仅需要大小为256的基本词汇表。然而,直接将BPE应用于字节序列会导致次优合并,这是因为BPE使用基于贪婪频率的启发方式来构建token词汇表。我们观察到BPE包括许多版本的常见词汇,如dog,因为它们出现在许多变种中,如 dog. dog! dog? . 这导致有限词汇时隙和模型容量的次优分配。为避免这种情况,我们会阻止BPE跨任何字节序列的字符类别的合并。空格是一个例外,它显着提高了压缩效率,在多个词汇标记中仅添加了最少的单词碎片。
这种输入表示允许我们将字级LM的经验益处(the empirical benefits)与字节级方法的通用性结合起来。由于我们的方法可以为任何Unicode字符串分配概率,因此我们可以在任何数据集上评估我们的LM,而不管预处理,标记化或词汇大小。
模型
我们使用基于Transformer(Vaswani et al., 2017)的LM架构。 该模型的细节基本遵循OpenAI GPT模型 (Radford et al., 2018) ,仅进行了少量的修改。层标准化(normalization) (Ba et al., 2016)被移动到每个子锁的输入,类似于预激活残差网络(He et al., 2016),并且在最终自注意块之后添加了额外的层标准化。使用了修改的初始化方案,该方案考虑了具有模型深度的残差路径上的累积。 我们在初始化时将残差层的权重缩放1/N倍,其中N是残差层的数量。 词汇量扩大到50,257。 我们还将上下文大小从512个token增加到1024,并使用更大的批量尺寸512。
实验
我们对四个LM进行了训练和基准测试,其大小均为对数均匀。 结构总结在表2中。最小的模型等同于原始GPT,第二小的模型相当于BERT的最大模型(Devlin等,2018)。 我们最大的模型,我们称之为GPT-2,比GPT的参数多一个数量级。 每个模型的学习率都是手动调整的,以便在5%的WebText样本中保持最佳的困惑。考虑到更多的训练时间,所有模型仍然对WebText欠拟合并且持续存在困惑。
语言模型
作为实现zero-shot任务转移的第一步,我们有兴趣了
剩余内容已隐藏,支付完成后下载完整资料
资料编号:[591052],资料为PDF文档或Word文档,PDF文档可免费转换为Word
您可能感兴趣的文章
- 饮用水微生物群:一个全面的时空研究,以监测巴黎供水系统的水质外文翻译资料
- 步进电机控制和摩擦模型对复杂机械系统精确定位的影响外文翻译资料
- 具有温湿度控制的开式阴极PEM燃料电池性能的提升外文翻译资料
- 警报定时系统对驾驶员行为的影响:调查驾驶员信任的差异以及根据警报定时对警报的响应外文翻译资料
- 门禁系统的零知识认证解决方案外文翻译资料
- 车辆废气及室外环境中悬浮微粒中有机磷的含量—-个案研究外文翻译资料
- ZigBee协议对城市风力涡轮机的无线监控: 支持应用软件和传感器模块外文翻译资料
- ZigBee系统在医疗保健中提供位置信息和传感器数据传输的方案外文翻译资料
- 基于PLC的模糊控制器在污水处理系统中的应用外文翻译资料
- 光伏并联最大功率点跟踪系统独立应用程序外文翻译资料


