
英语原文共 10 页,剩余内容已隐藏,支付完成后下载完整资料
加氢裂化反应器的动态非等温模型:通过集总法开发模型并应用于工业装置
摘要
加氢裂化作为一个重要的炼油工艺,是在催化反应器中将重石油馏分转化为有价值的产品。由于涉及大量的组分和复杂反应,加氢裂化的建模是一个具有挑战性的任务。本文中,利用连续集总法,一个动态的、非等温的加氢裂化反应器模型被建立,该方法把复杂的反应混合物视为一个连续体。在这种情况下,集总组分的分类是根据反应混合真实沸点的单调函数。物质和能量平衡以积分微分方程的形式发展。预测和确认重要的建模参数所使用的数据来源于一个工业反应器。对如反应器温度、产品产量和氢气消耗量等模型输出量的稳态和动态的预测都表明与工业数据高度吻合。
关键字:加氢裂化;连续集总;反应器建模;参数估值
1.前言
加氢裂化作为是一个催化过程,在石油精炼厂中被用来将高沸点、高分子量烃类转化为较轻的烃类产品像汽油、石脑油、煤油、柴油。加氢裂化是一个重要的和灵活的炼油工艺,因为它可以处理广泛的多种多样的瓦斯油,将其转化为一系列的改善的、低硫低杂质的、有价值的产品。对环境问题的关注、对低硫柴油和高发烟点航空煤油需求的增长都在提高加氢裂化技术应用上扮演了重要的角色。
加氢裂化反应是在临氢状态下,较高温度(260 – 495℃)和较高压力(35 - 200 bar)下发生的。主要的反应是裂化反应和加氢反应。为了同时进行上述两个反应,采用双功能催化剂,如双金属化合物(如镍和钼)附着在酸性载体(如二氧化硅-氧化铝)上。酸性载体促进裂化反应,而金属则提供加氢功能。裂化反应时是吸热反应,但是由于加氢反应是高度放热的,所以整个加氢裂化反应是放热反应。
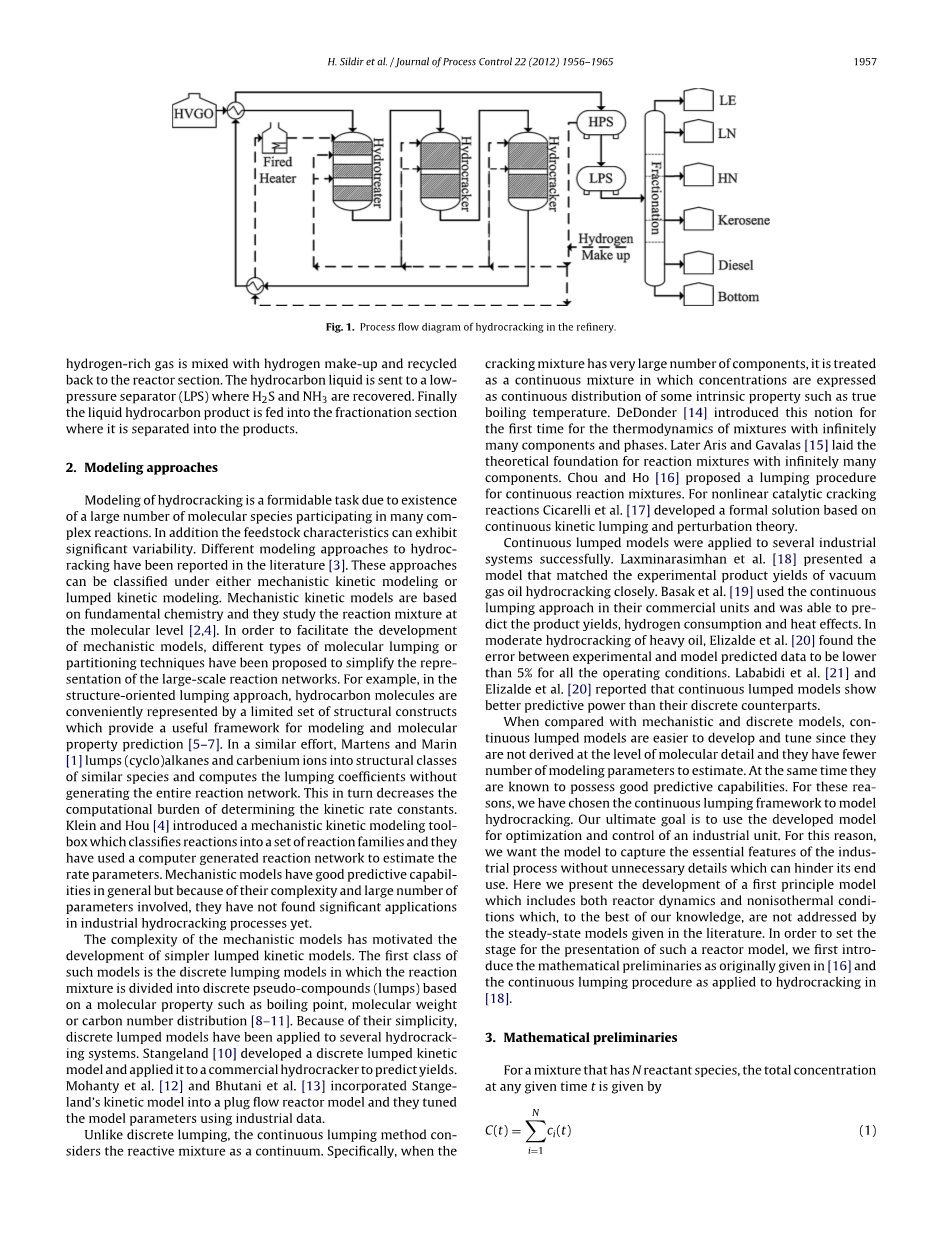
一个简化的加氢裂化装置流程如所图1示。重减压瓦斯油被反应器出来的废气预热,然后与氢气混合,氢气被燃料加热器加热,之后再进入第一阶段的加氢裂化装置,该装置被称为加氢精制反应器,在加氢精制反应器中,原料中的硫化物和氮化物转化为硫化氢和氨气而除去。同时,原料中的烯烃和芳香烃发生加氢反应。所有这些过程都会消耗氢气。有限的加氢裂化反应会发生在加氢精制反应器之中,因为反应器中的催化剂具有更高的加氢活性而不是裂化活性。加氢处理装置包括多个催化床,急冷氢被用于床层的冷却。如图中所示,加氢精制反应器中流出的液态流出物会进入裂化反应器中,在裂化反应器中,大多数的裂化反应发生在液相,加氢裂化装置是涓流床反应器,在反应器中液相里由重瓦斯油原料组成。氢气在气相,催化剂存留在固相。加氢裂化反应的是很复杂的,包括加氢反应、脱氢反应、贝它断裂反应、异构化反应。
从加氢精制反应器中流出的液体中不再含有硫和氮的杂质,而是绝大部分由饱和烃组成。反应器的产物与水混合。为了减少氨对管道的腐蚀,流出物进入一个高压分离器,在分离器中,流出物将分离成富氢气体、液烃和水。富氢气体和补充氢气混合一起循环回反应器再次利用。液烃被送入一个低压分离器,硫化氢和氨气会恢复。液烃会进入分馏部分,然后被分离成各种产品。
2.建模方法
加氢裂化的建模是一项艰巨的任务,因为存在大量多种分子参与到复杂的反应中。另外原料的特性也展示出来多变性。不同的加氢裂化建模方法已经在文献中有了报道,这些方法可分类为机械的动力学模型或集总的动力学模型。机械的动力学模型以基本化学为基础建立起来,它们在分子的水平研究反应混合物。为了帮助建立机械模型,不同类型的分子集总或分区技术用来简化大尺度反应网络的表征。比如,在适合构造的集总方法中,烃分子被一组有限的结构上的构想所方便地代表,这提供了一个有用的框架来建模和预测分子性能。在一个类似的工作中,Martens和Marin 把烷烃和碳正分子集总为结构类似的一类,估计集总系数,而不需要建立其余的反应网络。这反过来减少了确定动力学反应速率常数的计算负担。Klein 和 Hou 介绍了一种机械的动力学模型工具箱,它将反应分成不同的反应家族,他们利用电脑建立反应网络,来预测反应参数。机械模型一般有好的预测能力,因为它们的复杂性并包括大量的参数。但是它们还没在工业加氢裂化中建立重要的应用。
机械模型的复杂性促使了更简单地集总动力学模型的发展。这样的模型首要的是离散的集总模型,基于分子性质的不同,反应混合物被分为离散的虚拟的化合物,这些分子性质包括沸点、分子量或碳原子数的分配。因为它们的简易,离散集总模型已经被应用于数个加氢裂化反应体系。Stangeland开发了一个离散的集总模型并且把它应用于商业的加氢裂化装置来预测产量。Mohanty等人和Bhutani等人改进Stangeland的动力学模型为一个平推流反应器模型,并且他们用工业数据来调整模型参数。
与离散集总不同,连续集总法将反应混合物视为一个连续体。特别是当裂化混合物有大量的化合物,它们被视为一个连续的混合物,它们的浓度是连续分布的,像一些固有性质一样,如真实沸点温度。DeDonder首次引入这个概念,为的是包含无穷多的组分和相的混合物的热力学。之后,Aris和Gavalas为无穷多组分的混合物建立基础理论,Chou和Ho针对连续反应混合物提出了一个集总步骤。对非线性催化裂化反应,Cicarelli等人基于连续动力学集总和微扰理论开发了一个形式解。
连续的集总模型已经成功的运用于数个工业体系。Laxminarasimhan等人提出了一个模型,该模型与减压瓦斯油加氢裂化的实验产品产量非常匹配。Basak等人将连续集总方法用于他们的商业化生产单元,能够预测产品产量、氢气的消耗量和耗能量。在重油的适度加氢裂化中,Elizalde等人发现在所有的操作条件下实验数据和模型预测数据的误差都低于5%。Lababidi等人和Elizalde等人称连续集总模型显示了比离散集总模型更好的预测能力。
与机械模型和离散的集总模型相比较,连续集总模型更容易建立和优化,因为它们不是在分子水平被分开,它们有更少的模型参数需要估值。另一方面它们用于好的预测能力。基于这些原因,我们选择连续集总结构来建立加氢裂化的模型。我们的首要目标是利用开发的模型来优化和控制一个工业单元。因为这个原因,我们希望该模型能抓住工业过程中的一些影响应用必要的特征而不是不需要的细节。这里我们展示第一原则模型的发展,它同时包括反应动力学和非等温条件,就我们所知,这不是文献中报道的定态模型。为了表示这样的反应器模型,我们首先介绍相关的数学上基础和集总建模步骤。
3.数学基础
对于一个有N个组分的混合物,在任何一个给定时刻的总浓度由式1给出,其中ci是第i个反应物的浓度,ki为反应度,Ct为总浓度。
Chou 和 Ho用式1来近似的计算离散混合物,这是浓度是一个反应度k的连续函数。在这种做就完成了一个坐标变换,将离散的i转化为连续的k。i和k之间的一一关系由式2给出。
N趋于无穷时,D(ki)成为一个k的连续函数的和D (k)dk代表组分的数量它具有k和k dk之间的反应性。因此D(k)是一个组分类型分布函数,满足组分浓度归一:
有了这些定义,那么有一个公式可以代表这些离散的混合物:
在这个公式里,c(k,t)是反应物在连续的混合物中t时刻、反应度为k时的浓度。
因此,组分类型分布函数D(k)提供离散和连续之间的一致性。实验证据表明,加氢裂化反应活性与真正的沸点(真沸点)之间的单调增加关系符合一种幂律关系。
alpha;和kmax是参数,theta;是标准化的真实沸点。
在式子7中TBP(l)和TBP(h)是反应混合物中最低和最高的真是沸点。Kmax是最高沸点的组分的活性。运用D(k)等的定义,我们可以得到:
该式子满足式3的约束。
在文献里,这是这种形式的组分分布函数D(k)被用于所有的加氢裂化连续集总研究。注意,浓度c(k,t)取决于进料的浓度。然而D(k)只取决于反应物的组分类型,它独立于每个反应物的浓度。
3.1产量函数
在加氢裂化中,长链的烃类会断裂为短链的产物。我们用K和k分别代表
长链和短链的活性。产量分布函数p(k,K)代表了活性为k的组分在加氢裂化反应中由活性为K的重组分转化而来的形成过程。分析一些直链烷烃、芳香烃、烯烃在加氢裂化实验数据,Laxminarasimhan等人发现可以用一个高斯分布函数描述产量的分布,这种描述和事实非常相符。产量函数仍然只是反应活性k的函数,式子如下:
图2中展示三种不同活性K的典型产量曲线。
它是观察低反应活性的短链烷烃得到的,收率曲线的峰相对较窄较高,因为发生裂化的组分较少。相反的,收率曲线更宽的对应的是更长的烷烃,它们有更高的活性。应当注意的是,当kgt;K时,p(k,K)=0,因为按照定义,裂化成更长链的烷烃是不可能发生的。当k=0时,上述公式变为了:
p(0,k)应当是一个非零的很小的数,应为具有最小的反应活性的组分在裂化体系里的含量是微不足道的。因此,模型参数delta;被视为是一个小的数,公式中主要的模型参数a0、a1通过与工业数据相匹配而估计其值。这两个参数很重要,它们的值决定了加氢裂化产品的收率分布。
收率分布函数必须满足物料平衡的约束:
这个式子表达了总的收率一定要等于1,为了符合式11,归一化因数S0由下式规定:
4.反应器模型的建立
加氢裂化反应装置采用涓流床反应器,在反应器中,液相由重瓦斯油原料组成,氢气存在于气相之中,催化剂存在于固相上。每一个催化床层都被冷却区域分开,这些冷却区域有计划的提供急冷氢来控制催化床层的温度,正如图3所示。为了不过度的使得模型变复杂,我们假定这是一个平推流反应器,反应在绝热条件下发生,并且氢气过量。反应被虚拟为一级均相反应,扩散阻力、加氢脱硫反应、加氢脱氮反应的影响被忽略掉,因为氢气的消耗量很少,大概只有进料质量的5%,所以流过反应器床层的原料的质量流率可是视为是恒定的。上述所说的处于简化目的假设在现实中已经被其他的研究者所使用了。然而无论如何,我们建立的模型并不像之前文献中所报道的模型,我们并没有假设体系是定态的这个条件,所以所开发出来的模型可以用来对反应器进行动态的分析与控制。
有了以上这些假定,反应组分的质量守恒就限于了液相,这种限制也不是明确的,下面这个式子表达了非定态的质量守恒:
上述为考虑物料平衡影响,在之前的文献报道中的一些加氢裂化装置模型并未包括能量平衡在里面,所以这些模型不能预测一般装置中的温度效应。引入液相中的能量平衡,我们可以得到:
4.1 确定Cp(k)与 Hr(k)值
反应器模型的建立需要知道热容的分布情况和反应热,这些是包含在反应活k的函数之中的。Mohanty等人利用罗宾逊状态方程、逸度系数和过量焓计算出来离散模型中个体组分的热容。
它是观察到的热容的计算与真沸点单调减少。特别是它减少线性高真沸点范围涵盖大部分的操作条件。当我们计算使用现有相关文献中的热容,我们观察到相同的趋势。同时,石油馏分的热容相关性液相可以在误差高达20%。因此,而不是使用一个特定的联系,我们已经确定的热容的线性关系:
反应热的计算如下式:
4.2计算氢气的消耗量
氢气的消耗量可以由产品中含氢量和原料中含氢量的差异而求得。计算式子如下:每千克原料的耗氢量
4.3急冷氢流率计算
急冷氢被用于反应器两床层之间,提供床层的冷却作用,保证床层的进口温度在想要达到的温度点上。同时急冷氢也可以为加氢裂化反应提供额外的氢气来参与反应。因为缺少催化剂,在床层之间的冷却区段内是不会发生加氢裂化反应。当床层的进口浓度确定了之后,相应的所需要的急冷氢流率将由一下两个式子所决定。
5.模型参数的估值
参数的估值直接关系到是否能确定合理的模型参数,以使得建立的模型可以准确地预测工业数据。像在许多其他工业系统中一样,加氢裂化反应的运行会因为进料性质、催化剂、操作条件而存在一定程度的变化。因此必须使用一组代表性的工工业数据来估计实际参数的值。
下面考虑如何选择工业数据:为了训练数据,我们选择工业数据涵盖近两个月的时间。考虑一个较长时间段,将引入重要的因素催化剂活性的变化,而相反的选择一个更短的时间段内的数据,将限制预测范围或着模型的预测能力。研究中所用的每个数据都包含每日相关数据的平均水平。
6.结果
模型的参数根据参数估计值进行了调整,调整后的模型的性能显示在表3进行,包括训练和验证的性能。真实的床层出口温度、产品产量和氢气流率被拿来与模型的输出值相比较。模型使用和工业上相同的分馏温度划分,这要两者就得到相同的产品,可以用来比较产量。我们从所列出的平均误差的量级可以看出,模型预测值和工业数据的一致性很好。产品的收率误差低于10%,绝大多数情况下,个体产品的误差低于4%。温度的误差也低于一定的程度,比过程和测量的误差要小。在工业生产中,补充氢保持了氢气总量的持续一致,因此,在表中,由模型计算出的总的氢气消耗量被拿来与工业中测得的氢气补充的总量来比较。而急冷氢和氢气消耗量两项的预测效果也是可以接受的。急冷氢和补充氢预测的平均绝对分别是名义上数值的6%和4%。
7.结论
利用连续集总方法,我们建立了一个工业加氢裂化
剩余内容已隐藏,支付完成后下载完整资料
资料编号:[154138],资料为PDF文档或Word文档,PDF文档可免费转换为Word
您可能感兴趣的文章
- 饮用水微生物群:一个全面的时空研究,以监测巴黎供水系统的水质外文翻译资料
- 步进电机控制和摩擦模型对复杂机械系统精确定位的影响外文翻译资料
- 具有温湿度控制的开式阴极PEM燃料电池性能的提升外文翻译资料
- 警报定时系统对驾驶员行为的影响:调查驾驶员信任的差异以及根据警报定时对警报的响应外文翻译资料
- 门禁系统的零知识认证解决方案外文翻译资料
- 车辆废气及室外环境中悬浮微粒中有机磷的含量—-个案研究外文翻译资料
- ZigBee协议对城市风力涡轮机的无线监控: 支持应用软件和传感器模块外文翻译资料
- ZigBee系统在医疗保健中提供位置信息和传感器数据传输的方案外文翻译资料
- 基于PLC的模糊控制器在污水处理系统中的应用外文翻译资料
- 光伏并联最大功率点跟踪系统独立应用程序外文翻译资料


